前回の 災害時でも利用可能なローカルネットワーク環境を構築する の補足的な記事になります。
災害時こそ生成AIを使って問題を解決したい場面があると思います。
普段使用している生成AIはWebサービスですから、当然インターネット接続が必要です。
そこで今回は、デスクトップアプリとしてローカルで完結するLLMであるLM Studioを使ってみます。
ローカルLLMの特徴
インターネット接続不要
ローカルLLMは前述の通りローカルで処理が完結しますので、インターネット接続が不要です。
そのため災害時でもPCが動く環境であれば使用できます。
料金不要
通常、生成AIのサービスは無料でも使えますが上限があり、上限に達すると一定時間使えなくなることがあります。
これを回避するために月額料金のかかる有料プランや、APIを利用する場合には使用量に応じた従量課金制の料金が設定されています。
ローカルLLMではこれらの料金がかかりません。
最新モデルと同等の処理はできない
ローカルLLMの処理能力はアプリが動作するPCの性能に依存しますので、巨大で高性能なインフラを駆使して動いている現行の生成AIサービスより処理能力は劣ります。
最新のAIモデルを個人のPCで動かすことは無理がありますし、そもそも公開されているローカルLLM用のモデルは最新ではありません。
PCでも動作するように、軽量化を中心としたカスタマイズがされています。
とはいえ、今回の試みのように「非常時にもAIのアシストが欲しい」という目的であれば十分な性能を持っています。
それなりのスペックのPCが必要
ローカルLLMが問題なく動作するにはある程度のスペックが必要となります。
Windowsの場合、必要なスペックの目安は以下の通り(※AI回答)。
| パーツ | スペック |
|---|---|
| GPU | NVIDIA RTX 3060以上 (VRAM 8GB〜12GB以上) |
| RAM (メモリ) | 16GB以上(32GBあると尚良し) |
| ストレージ | SSD必須(空き50GB以上) |
| CPU | Intel Core i7 / AMD Ryzen 7 以上 |
LM Studio
今回はローカルLLMのデスクトップアプリである LM Studio をインストールします。
私のWindows端末では軽量なモデルでも起動できなかったため、macOS端末を使用しました。
公式サイト
https://lmstudio.ai/ にアクセスし、Downloadボタンからインストールファイルを入手します。
インストール方法は、基本的に画面の指示に従って進めていけば問題ありません。
起動画面
インストール後の起動画面です。
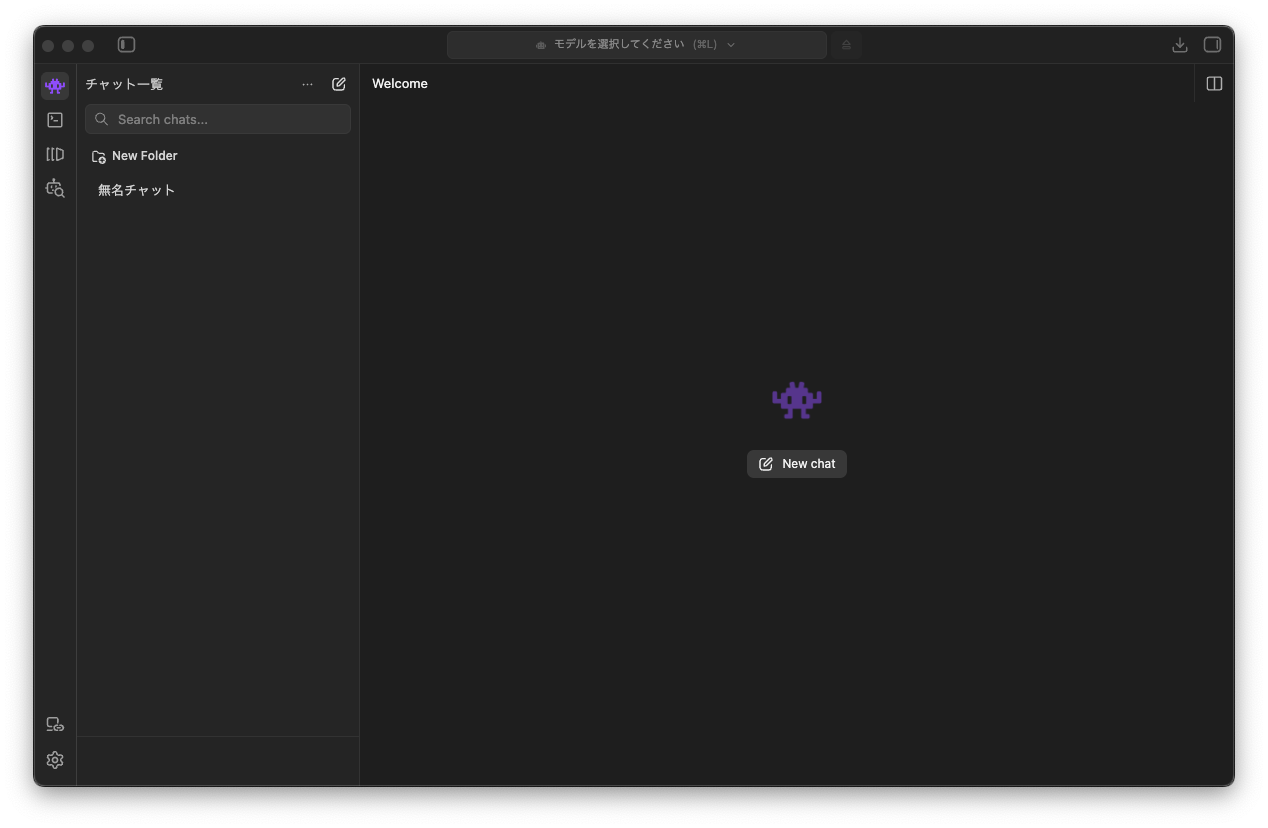
言語設定
日本語で使用したいため言語設定を変更します。
歯車アイコン → General → 言語から日本語を選択します。
AIモデルのインストール
Model Search アイコン → 対象のモデルを検索 → Downloadを実行します。
今回は軽量なGemma 4 E2Bを選択します。
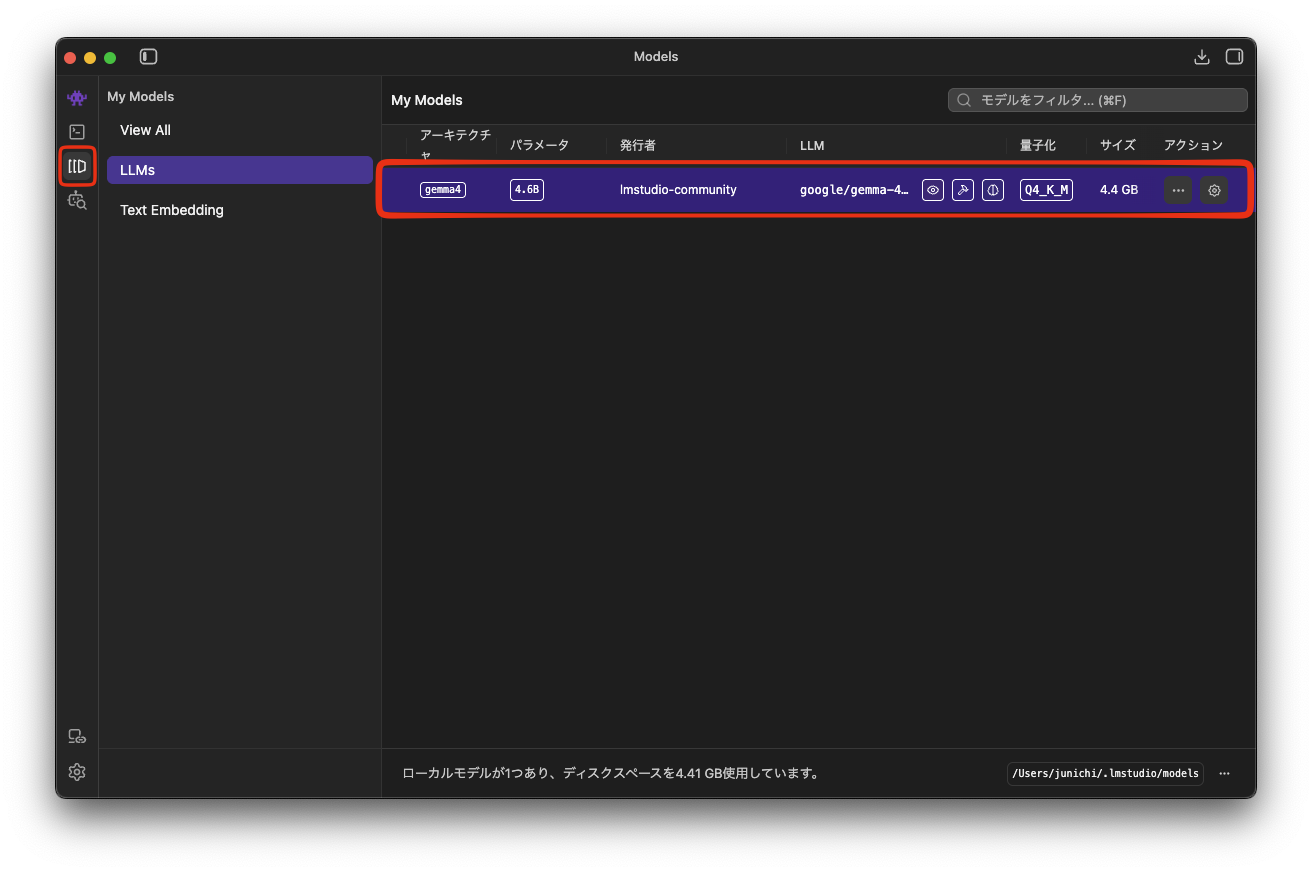
インストール済みモデルの確認
My Models アイコンをクリックすると、インストール済みモデルが表示されます。
インストール済みモデルの適用
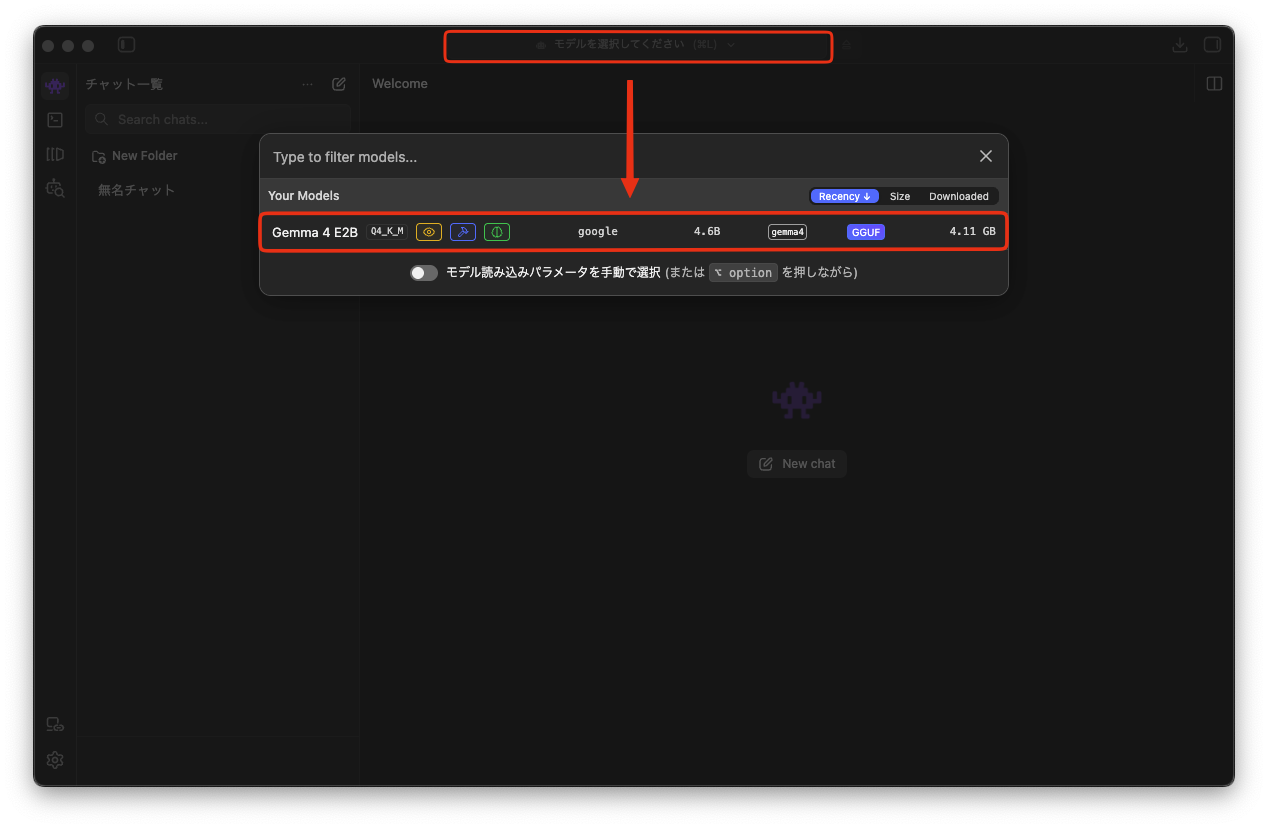
Chat アイコンからチャット画面を開き、画面上部のボタンからモデルを選択します。
ここで選択したモデルがメモリに読み込まれます。
チャットの実行
メッセージ送信
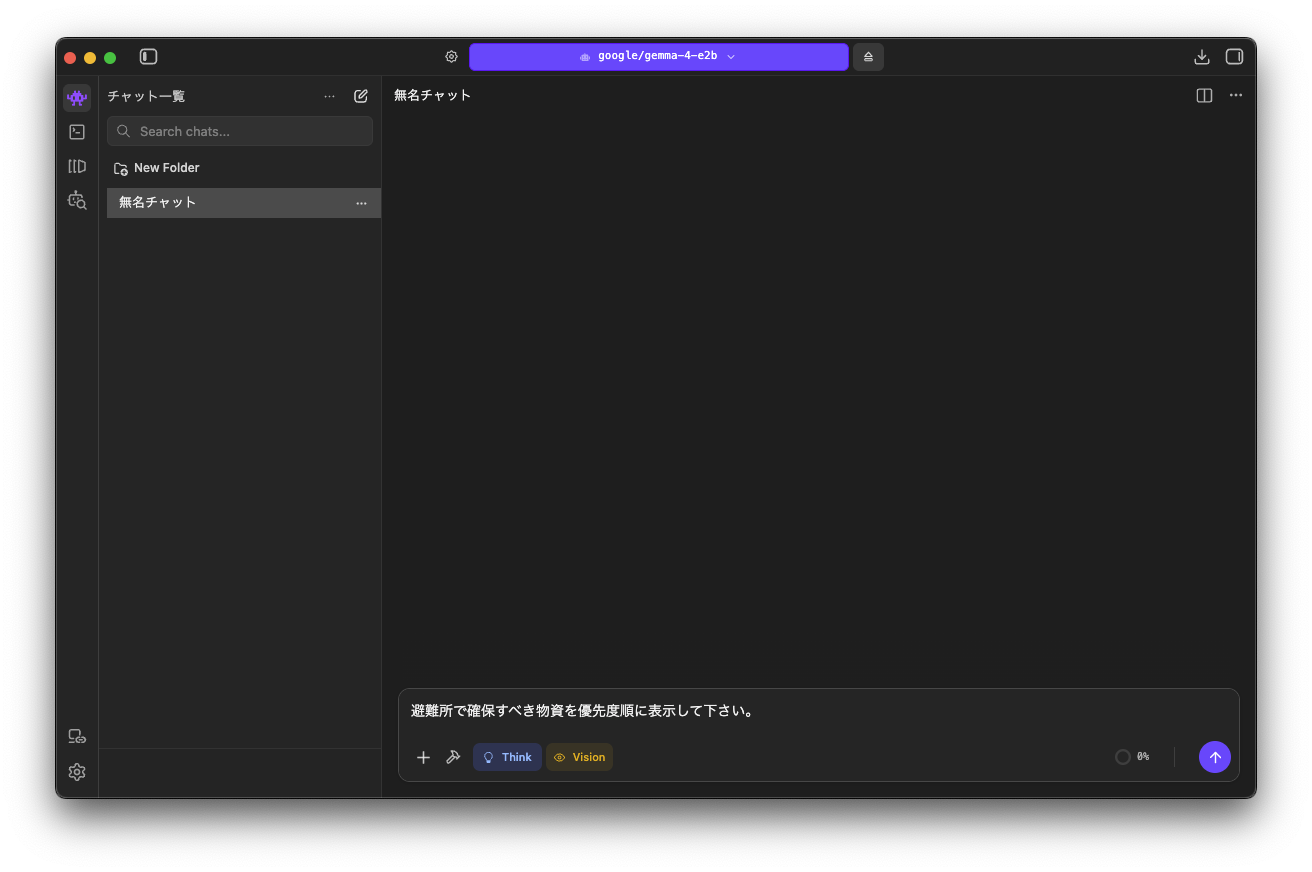
モデルを読み込み、通常の生成AIで利用するのと同様にチャットを開始します。
以下のメッセージを送ってみました。
避難所で確保すべき物資を優先度順に表示して下さい。
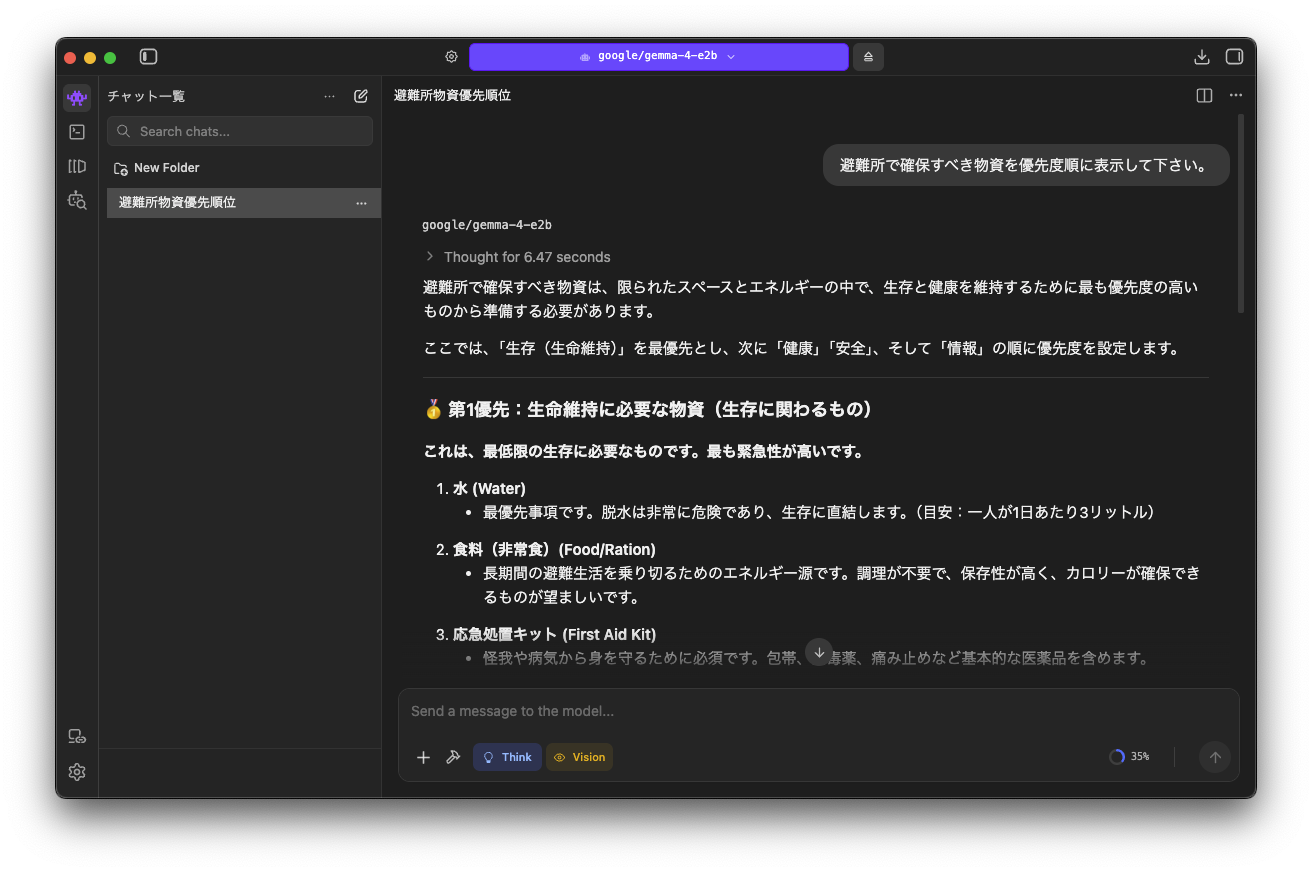
モデルからの回答
通常の利用と遜色のないレベルで回答してくれました。
処理速度については端末の性能依存になるとは思いますが、特に気にならない速度でした。
ローカルLLMに対してAPIを実行する
Webサービスの起動
LM StudioはAPIを介した処理が可能です。
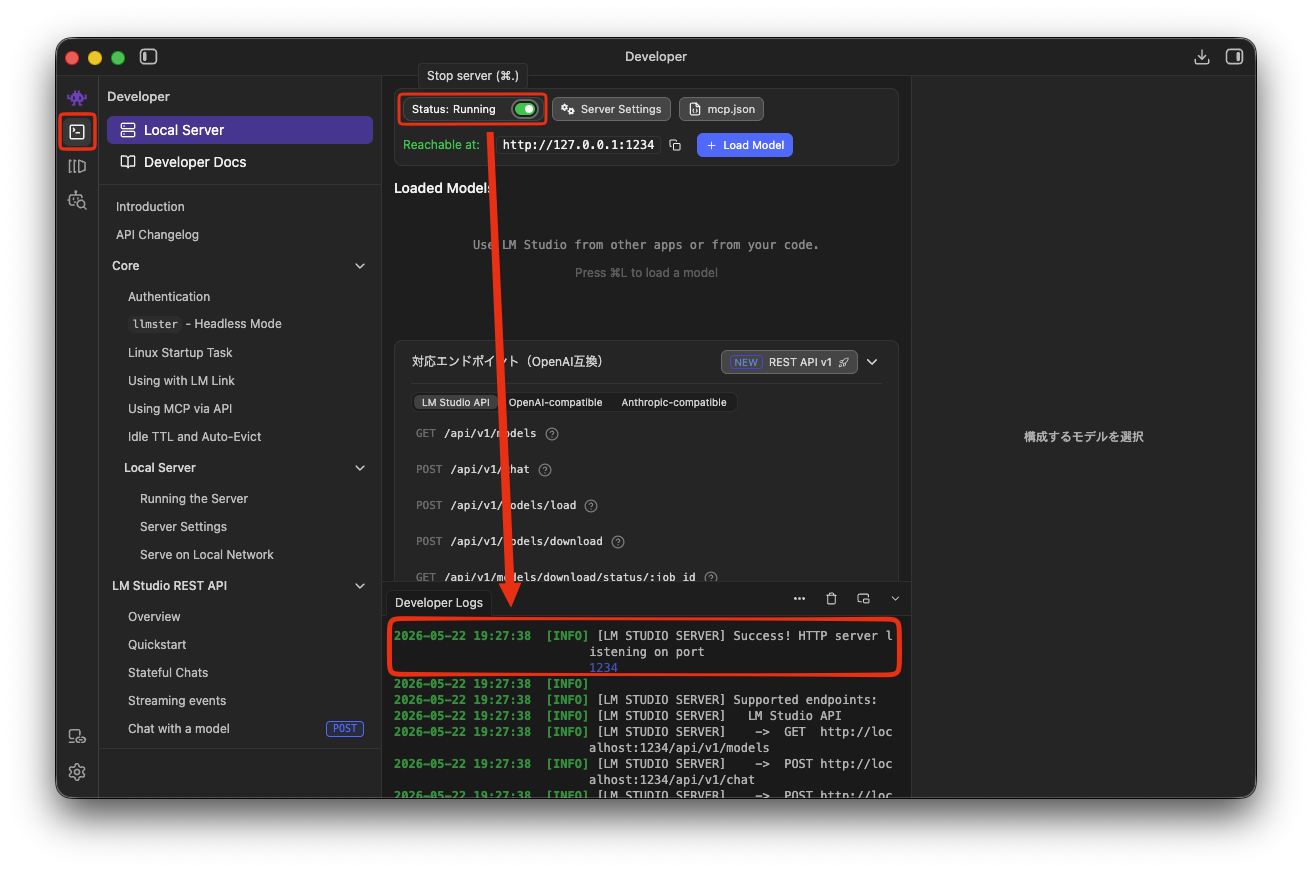
Developer アイコンから Local Server を開き Start Server を実行します。
Status が Running に変わると、ログメッセージからWebサービスが開始されたことがわかります。
また、リクエスト送信先となるIPアドレスとポート番号が表示されます。
リクエストを実行
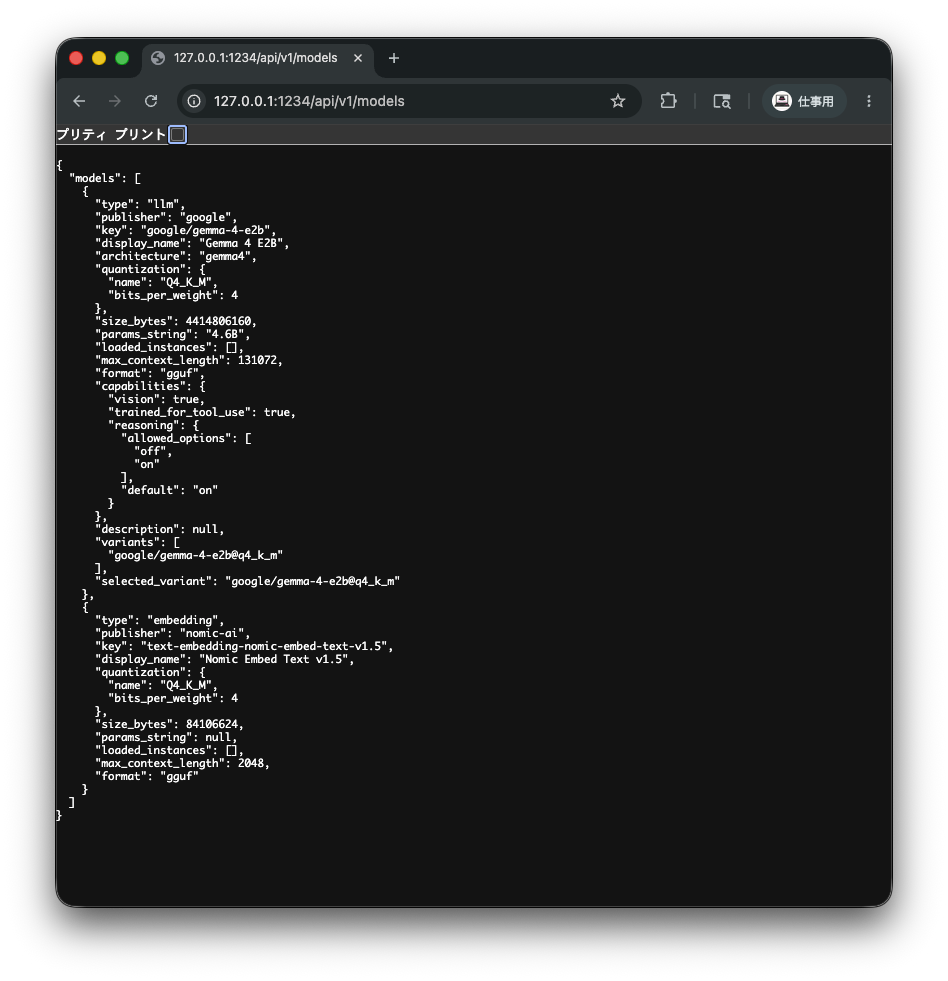
このIPアドレスに対しブラウザからリクエストを送ってみます。
LM Studioの画面に表示されているGETリクエストのエンドポイントである /api/v1/models にリクエストします。
ブラウザのアドレスバーに http://127.0.0.1:1234/api/v1/models を入力しアクセスすると、モデル情報のレスポンスが返ってきました。
まとめ
ローカルLLMはネット接続、利用料金なしで生成AIサービスを利用することができるため、災害発生時でも活用の道がありそうです。
特にLM StudioはAPI利用を前提とした設計になっているため、ローカル環境であってもAIのサポートを受けながらサービスを構築することも可能です。
注意点として、利用時はインターネット接続が不要でもインストールはインターネット接続環境下で行う必要があります。
非常時の準備に、ローカルLLMセットアップ済みのノートパソコンを加えておくのはいかがでしょうか。